Amazon S3¶
Alation can synchronize metadata about the files in your Amazon S3 buckets into the Alation catalog. Follow this guide to set up automatic syncing. First, you will need to create an instance role or a user account for Alation to access the data in Amazon S3 buckets. Then you will configure Alation and specify the files to sync.
Configuration in Amazon S3¶
Alation supports the authentication mechanisms as described in the following AWS article. You can use an IAM user or an IAM instance role to authenticate. In the S3 file system settings, if you leave both the Username and Password fields blank, Alation will attempt to use an IAM instance role to authenticate.
Note
From version 2021.3, you can use the Alation AuthService to authenticate with AWS IAM. See Configure MDE with AWS IAM Authentication.
If using an IAM instance role:
Create an IAM instance role for access to the AWS resources you wish to catalog in Alation. See add-role-to-instance-profile.
If using an IAM user:
Create an IAM user with an Access ID and Secret Key for Alation. You can refer to the following Amazon S3 documentation:
Permissions¶
Grant the IAM instance role or the IAM user the following permissions:
ListAllMyBuckets
ListBucket on all buckets you want to be synced into Alation
Why does Alation need ListAllMyBuckets permission?¶
ListAllMyBuckets is a permission that allows a user to see the list of buckets that exist. It does not mean that the user can read inside the buckets. Alation needs this permission to iterate through the list of buckets and sync the data in each bucket. Amazon S3 allows only two options, permission to list all the buckets in the account or no permission to list buckets in the account. There is no way to allow listing some buckets and not others. If you don’t want Alation to sync some buckets then you still need to give it ListAllMyBuckets but you can revoke the ListBucket permission for those buckets you want to restrict. The sync job will try to get the data in those buckets but move on when it gets permission denied.
Configuration in Alation¶
Only do this after the configuration in Amazon S3 is done.
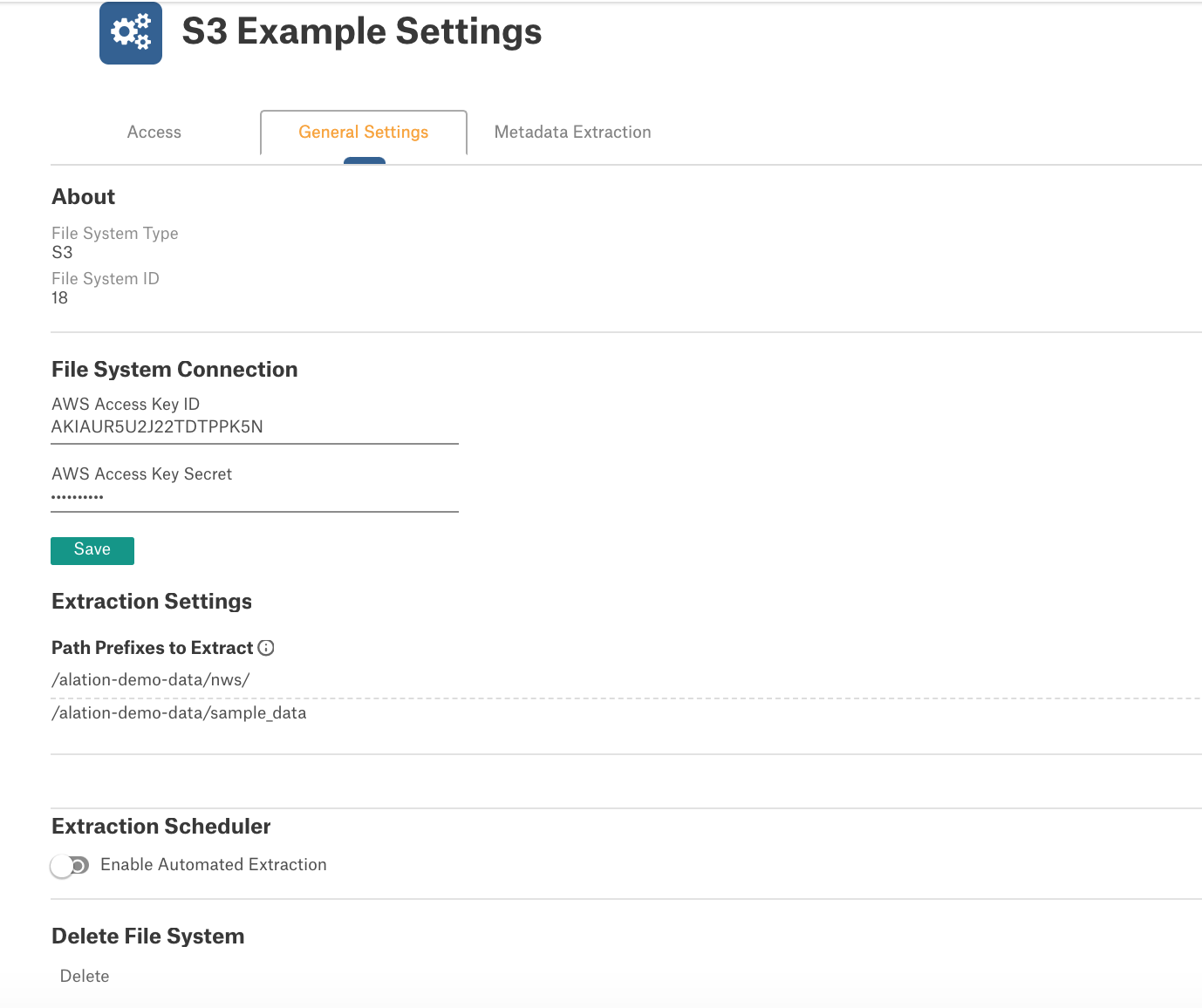
Add a new file system through the Sources > Add a File System page.
Choose the type as S3.
Alation will take you to the Settings page for your new file system when you save.
If using an IAM instance role, leave the Access ID and Secret Key fields blank and click Save.
If using an IAM user for authentication, enter the AWS Access Key ID and the AWS Access Key Secret and click Save.
From version 2021.3: if using the AuthService for authentication, see additionally: Amazon S3 File System Source.
Optionally, add a list of path prefixes to sync. If you do not specify any, then all will be synchronized. When this list is populated, only files that match one of the prefixes will be extracted. Prefixes should start with a delimiter. Add the bucket name as the first part of the path, for example: /directory/folder_to_be_extracted.
Note
It may be useful to limit the sync to a small section of your system the first time you sync in order to test the configuration and confirm it is working.
On the Metadata Extraction tab of the Settings, click Run Extraction. Wait for a few seconds. You should see a status update at the bottom of the page showing the extraction running. It may take some time.
Troubleshooting¶
The job fails and shows an error message in the UI¶
If the extraction failed with an error, read the message and try to match it to a category described below.
Authentication Error¶
Check your credentials, try re-entering them or logging in through a different system.
Permissions Error¶
If it is a permission error, the grants may not are done correctly. Confirm the steps 1 and 2 under Configuration in Amazon S3 are done. Sometimes, grants are different depending on which IP address the request is coming from.
Network Error¶
Confirm the Alation server has access to the internet so it can reach Amazon servers.
The job works but no files were synced¶
Confirm that the IAM user has permission to ListBucket for some buckets. Alation will skip over buckets that it doesn’t have permission to read without failing the syncing job so it’s possible that Alation can see the list of bucket names but could not read inside any of them.
Check your path prefix filters. Remember the bucket name must be the first part of the prefix. So if you have a bucket called logs and a file in that bucket called app.log if you only want to get that file you would add /logs/app.log as the path prefix.
I changed the filters and my old files are gone¶
This is the expected behavior. Only files that match your filters will show up in the catalog. If you don’t want to disturb your existing data you can add new filters and don’t change old ones. Your annotations to the old files will come back if you change the filters back and re-sync.