Elasticsearch¶
Applies from 2021.4
Alation has certified the Elasticsearch data source with the following CData driver:
cdata.jdbc.elasticsearch.ElasticsearchDriver.cdata.jdbc.elasticsearch
Alation can provide the required CData driver license for Parquet. Refer to How to get a CData Driver and use the scenario appropriate to your case.
Scope of Support¶
Supported as Custom DB with the CData Driver for Elasticsearch
Metadata Extraction (MDE)
Automated MDE
Data Profiling
Sampling
Compose
Lineage is not supported
QLI is not supported
Ports¶
Port 9700 must be open.
Service Account¶
Create the service account for Elasticsearch, refer to Elasticsearch Service Account or use any relevant mechanism to create an ElasticSearch user/password for service account.
Permissions¶
Make sure that the service account has the following permissions:
auto_configure
delete (optional as the driver supports deletes)
delete_index (optional as the driver supports deletes)
index
read
view_index_metadata
write
Required Information¶
JDBC URI for the Elasticsearch data source
JDBC URI¶
When building the URI, include the following minimal list of required parameters:
Server - The host name or IP address of the Elasticsearch REST server.
Port - The port for the Elasticsearch REST server.
DataModel - Specifies the data model to use when parsing Elasticsearch documents and generating the database metadata.
FlattenObjects - Set FlattenObjects to true to flatten object properties into columns of their own. Otherwise, objects nested in arrays are returned as strings of JSON.
FlattenArrays - Set FlattenArrays to 1. By default, nested arrays are returned as strings of JSON.
RTK Key - When you purchase a CData driver from Alation, you are provided an RTK that needs to be included into the URI. If you purchased the driver from CData, you should have a license file that needs to be placed on the Alation server together with the driver .jar file.
The following parameters can be optionally included in the URI:
ProxyServer - The hostname or IP address of a proxy to route HTTP traffic through.
ProxyPort (If proxy connection is used) - The TCP port the ProxyServer proxy is running on.
ProxySSLType - The SSL type to use when connecting to the ProxyServer proxy.
SSLServerCert - The certificate to be accepted from the server when connecting using TLS/SSL.
Using these values, construct the URI according to the pattern given below and proceed to adding the data source.
Use the following format for the JDBC URI:
elasticsearch://<Server>:<Port>;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;RTK=<RTK_Key>;
Example:
elasticsearch://localhost:9700;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;RTK=444752465641535552425641454E545042424D33323632390000000000000000000000000000414C5800005559475655474E4E464242370000;
Use the following format for the JDBC URI if proxy connection is used:
elasticsearch://<Server>:<Port>;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;ProxyServer="localhost";ProxyPort="<Port_Number>";ProxySSLType="NEVER";SSLServerCert=*;RTK=<RTK_Key>;
Example:
elasticsearch://localhost:9700;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;ProxyServer="localhost";ProxyPort="8866";ProxySSLType="NEVER";SSLServerCert=*;RTK=444752465641535552425641454E545042424D33323632390000000000000000000000000000414C5800005559475655474E4E464242370000;
Set Up in Alation¶
Step 1: Add the CData Driver for ElasticSearch to Alation¶
Depending on how you purchased the CData driver, from Alation or from CData, the driver installation process will be different. Refer to Add the CData Driver into Alation Instance and use the scenario appropriate to your case.
STEP 2: Add a New Data Source¶
Add a new Data Source on the Sources page.
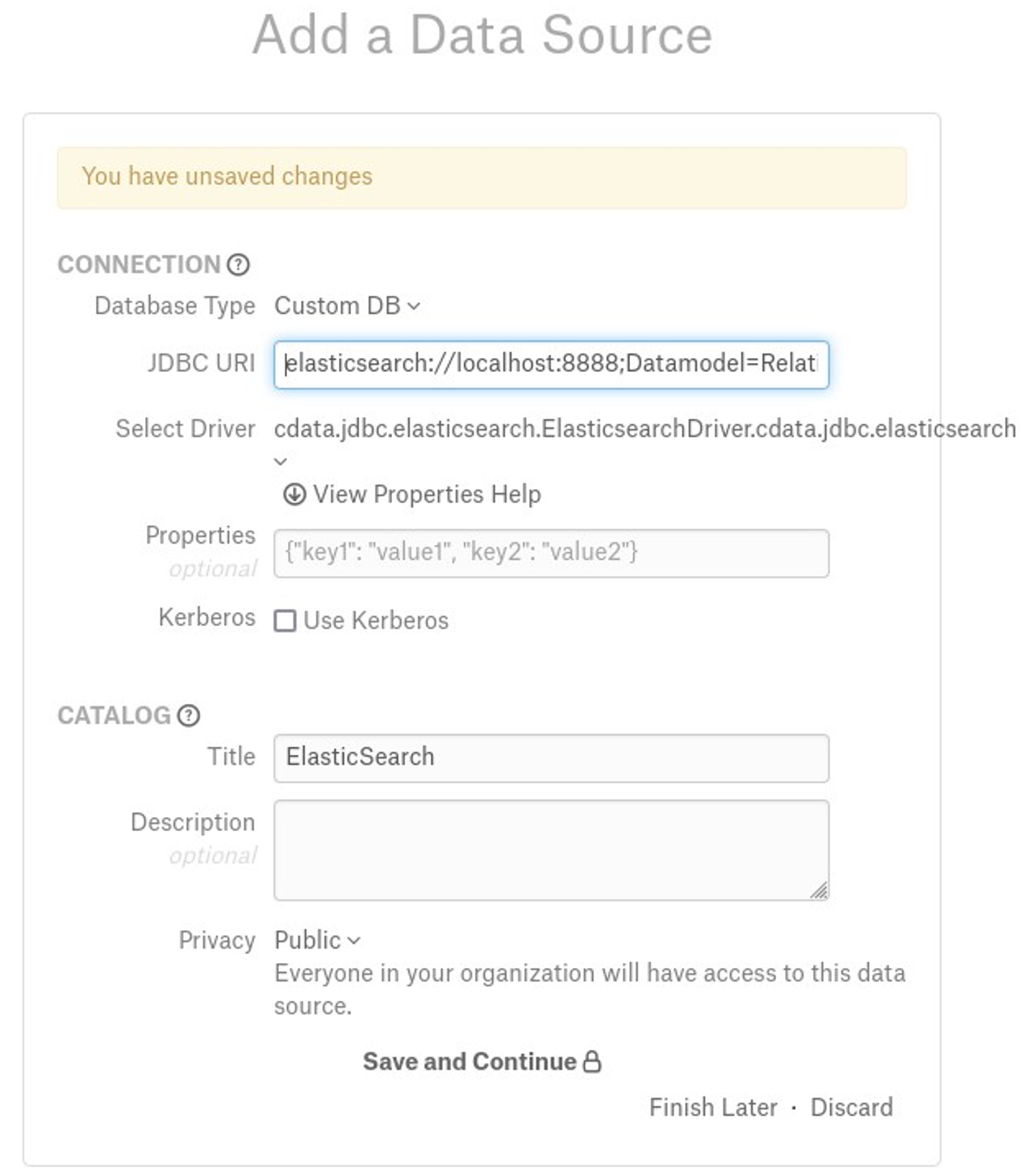
Step 3: Set up the Connection¶
On the Add a Data Source screen of the wizard, specify:
Database Type: Custom DB
JDBC URI: URI in the required format. See JDBC URI.
Example 1:
elasticsearch://localhost:9700;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;RTK=444752465641535552425641454E545042424D33323632390000000000000000000000000000414C5800005559475655474E4E464242370000;Example 2:
elasticsearch://localhost:9700;Datamodel=Document;FlattenObjects=True;FlattenArrays=1;ProxyServer="localhost";ProxyPort="8866";ProxySSLType="NEVER";SSLServerCert=*;RTK=444752465641535552425641454E545042424D33323632390000000000000000000000000000414C5800005559475655474E4E464242370000;Select Driver: select the JDBC driver for Parquet from the Select Driver drop-down list:
cdata.jdbc.elasticsearch.ElasticsearchDriver.cdata.jdbc.elasticsearch
Do not select the Use Kerberos checkbox
Click Save and Continue. The next wizard screen - Set Up a Service Account - will open.
Step 4: Enter Service Account Credentials¶
Select Yes.
Provide the username and password of the service account created for Alation.
Click Save and Continue. The next wizard screen, Configure Your Data Source, will open.
Step 5: Configure Your Data Source¶
Click Skip this Step. After this step, you are navigated to the Settings page of your data source.
Access¶
On the Access tab, set the data source visibility as follows:
Public Data Source - The data source will be visible to all the users.
Private Data Source - The data source will be visible to the users with Viewer role, Admin of this data source and the Server Admin for whom the permission is granted.
Add new Data Source Admin users in the Data Source Admins section.
Metadata Extraction¶
Configure and perform metadata extraction and verify the results:
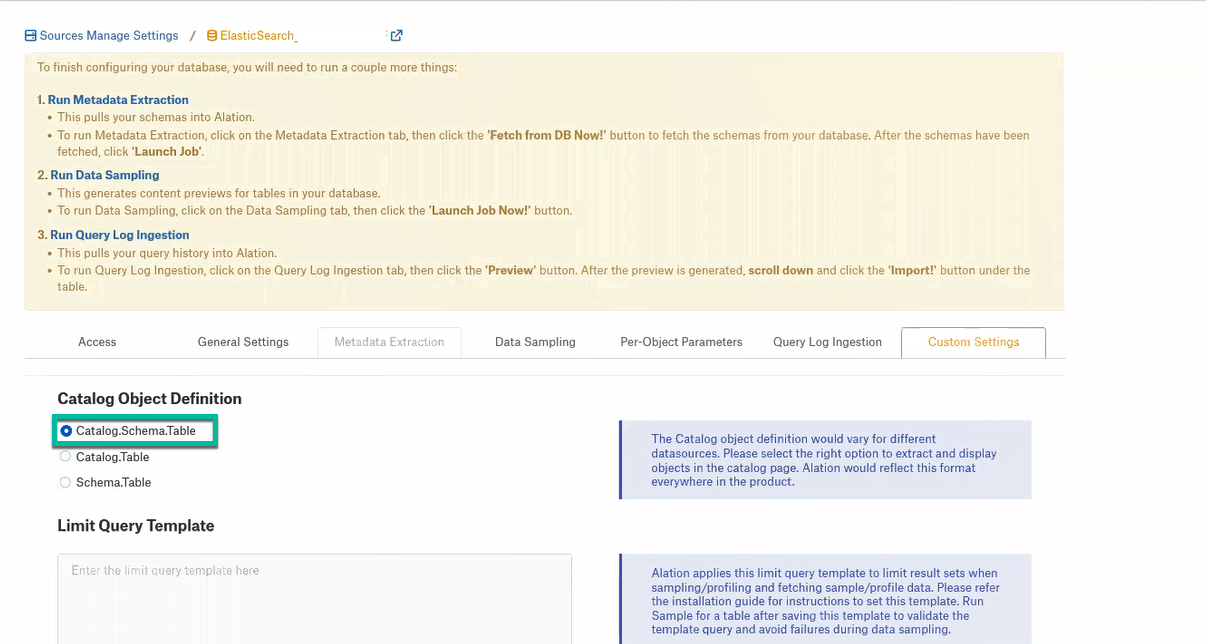
In Settings > Custom Settings, set the Catalog Object Definition to Catalog.Schema.Table:
In Settings > Metadata Extraction, set up and perform MDE. Refer to Metadata Extraction.
Profiling¶
Configure and perform Profiling :
Users can run a sample for an individual table on the Samples tab of the Table Catalog page or profile an individual column on the Overview tab of the Column page.
Automatic full and selective Profiling is supported.
Use the Per-Object Parameters tab of the Settings to specify which objects to profile.
Note
Make sure that the Skip Views checkbox of the respective schemas is unchecked to perform the Profiling.
Custom query-based Sampling is supported. Custom Query-Based Sampling allows you to provide a custom query for profiling each specific table.
Deep Column Profiling (Profiling V2 ) is supported.
Sampling¶
Perform Sampling: refer to Sampling.
Query Log Ingestion¶
Not supported.
Compose¶
Log into Compose:
Authenticate in Compose with your Amazon S3 credentials.
Use the Catalog.Schema.Table format for writing queries.
Troubleshooting¶
Refer to Troubleshooting for CData Data Sources.